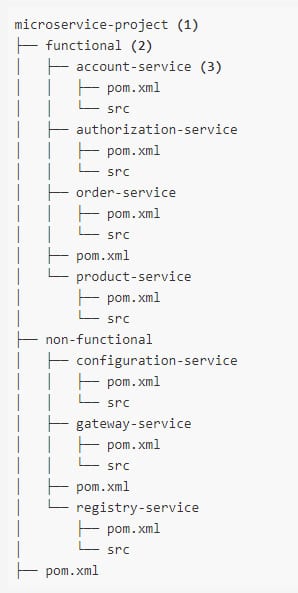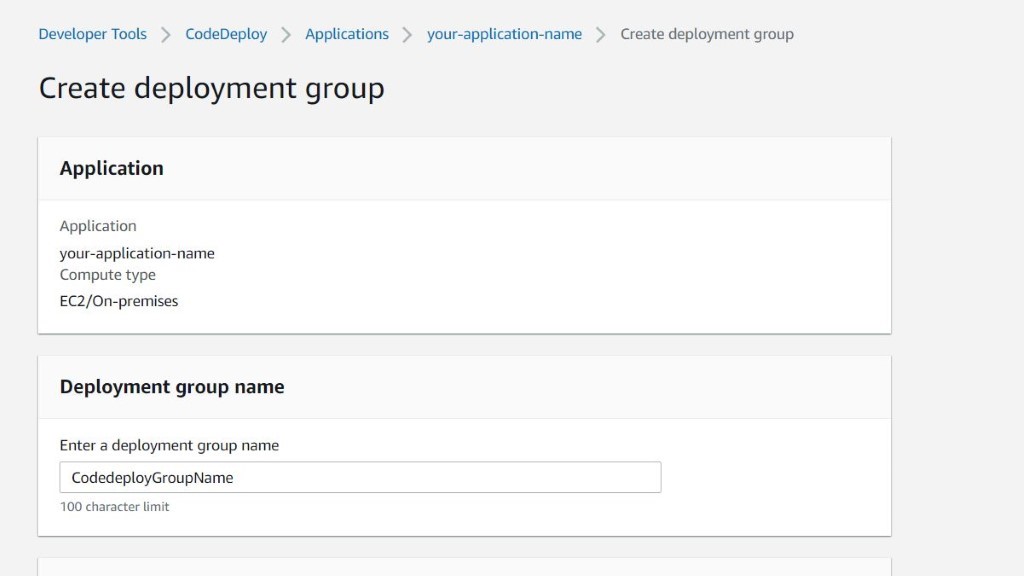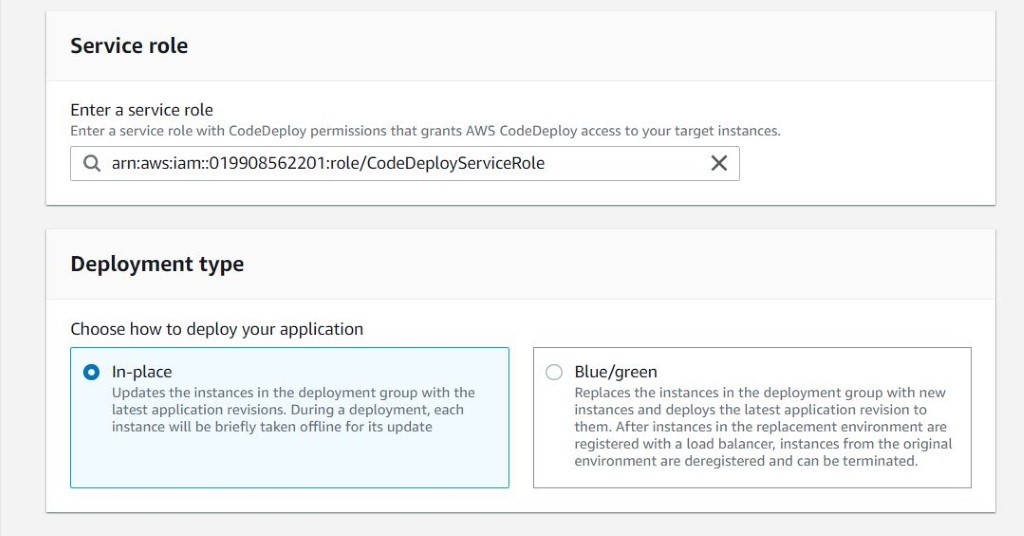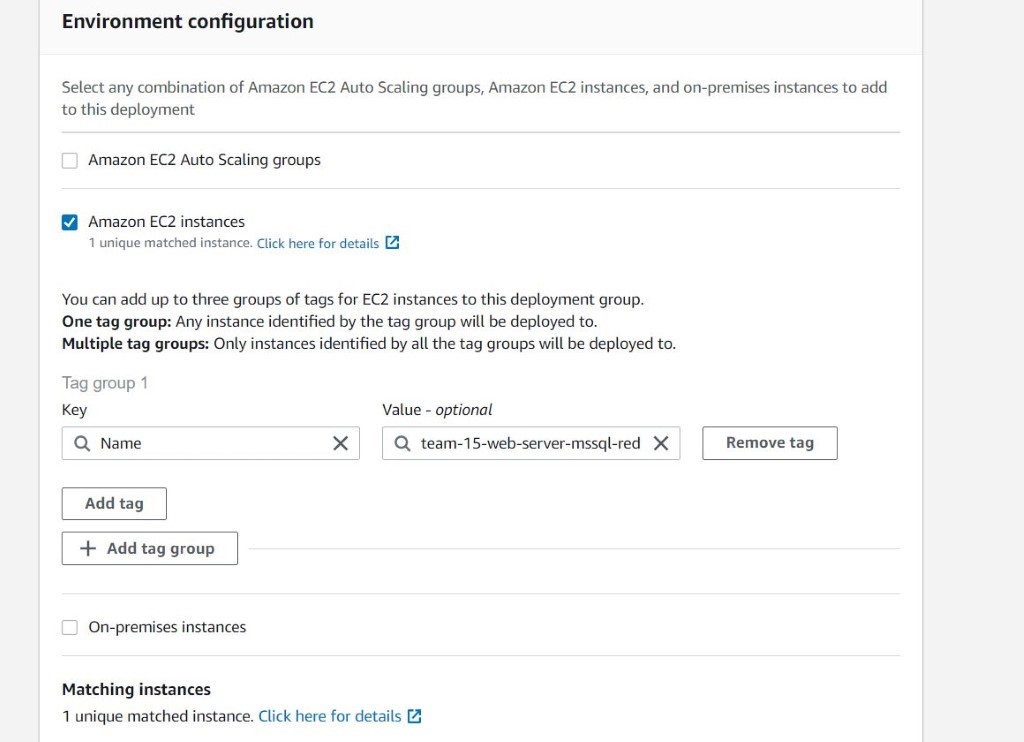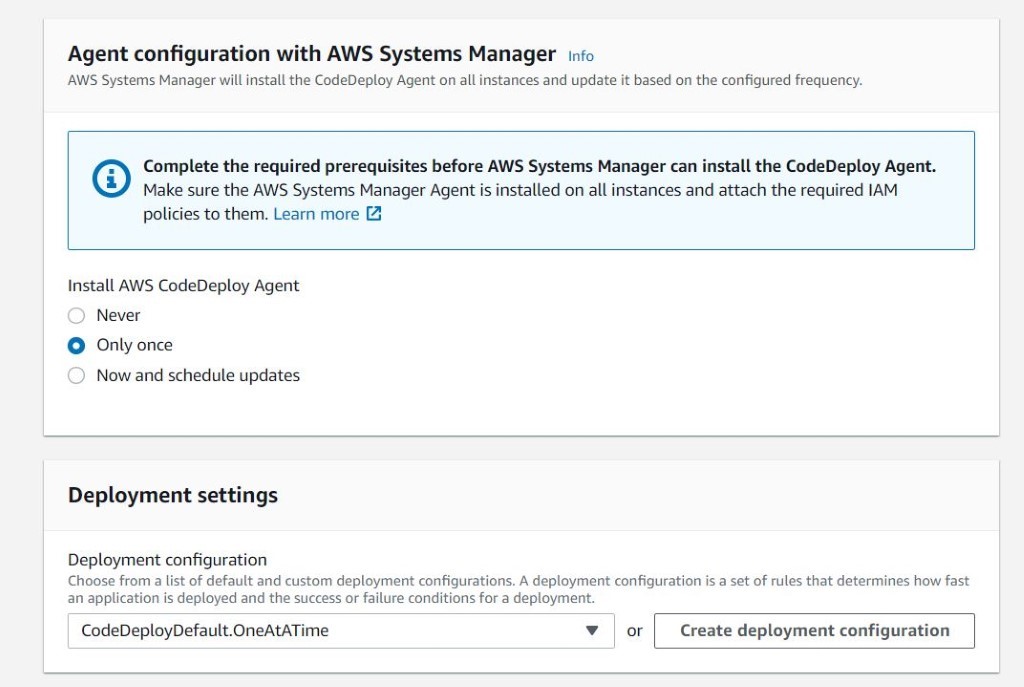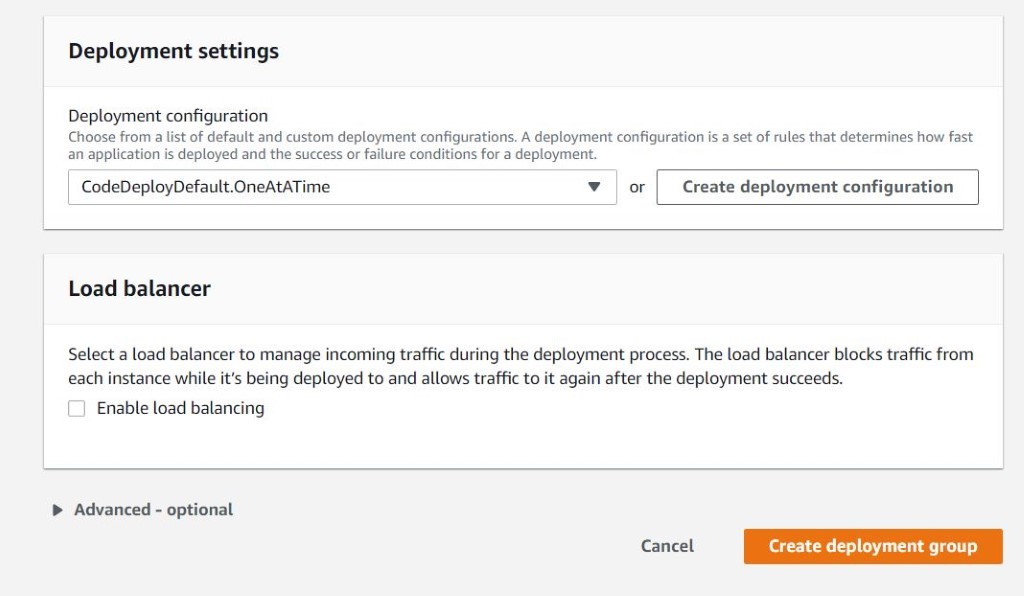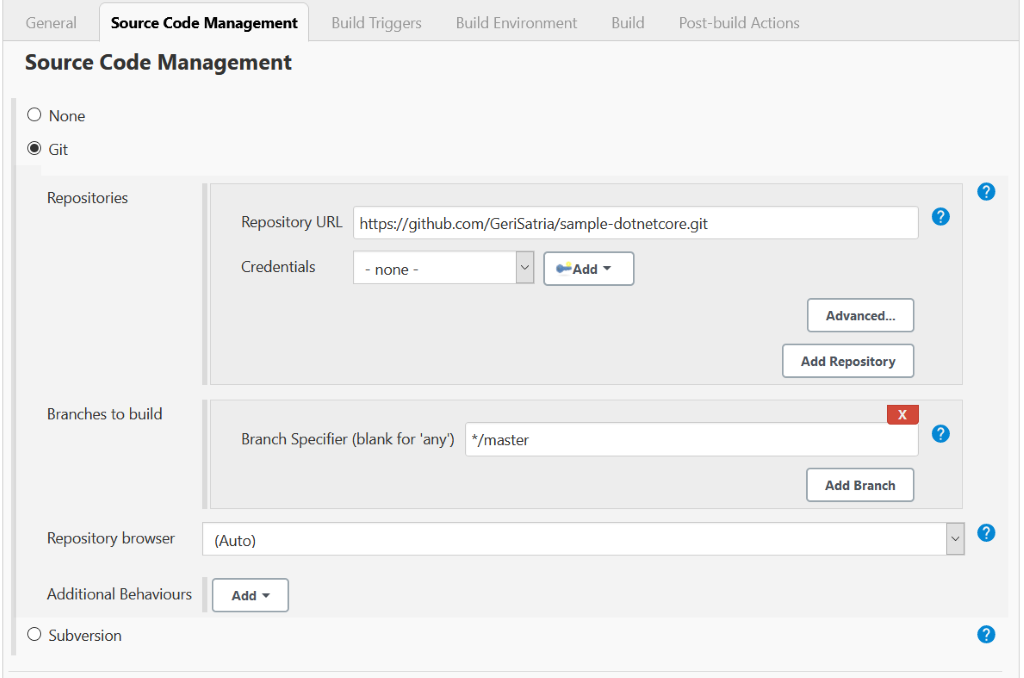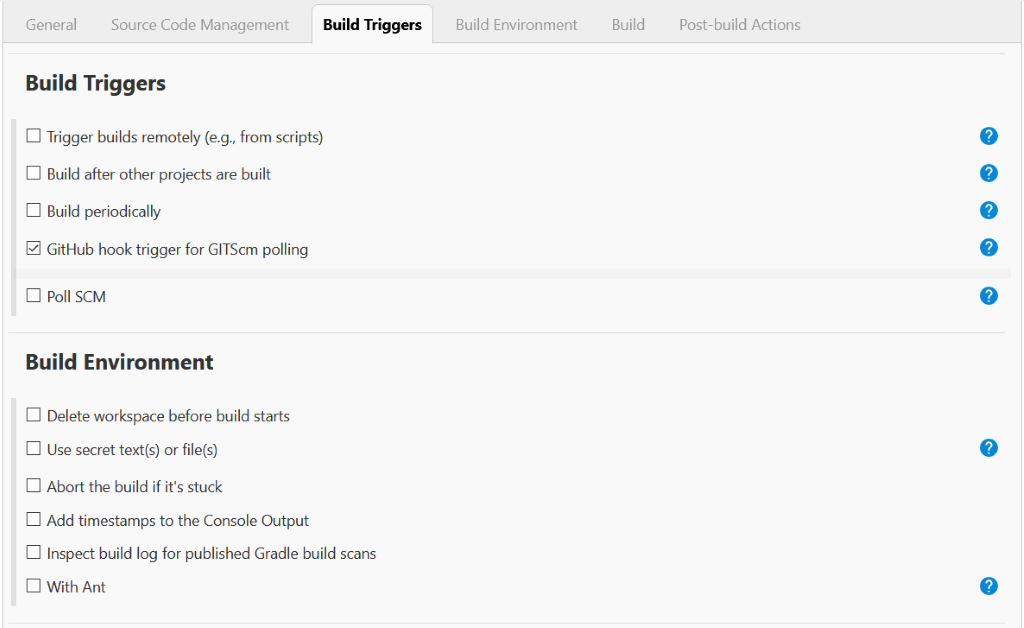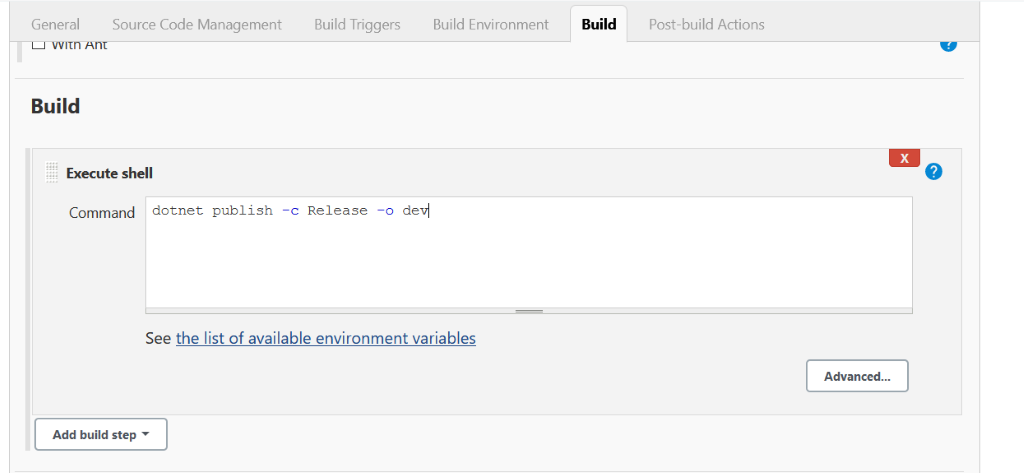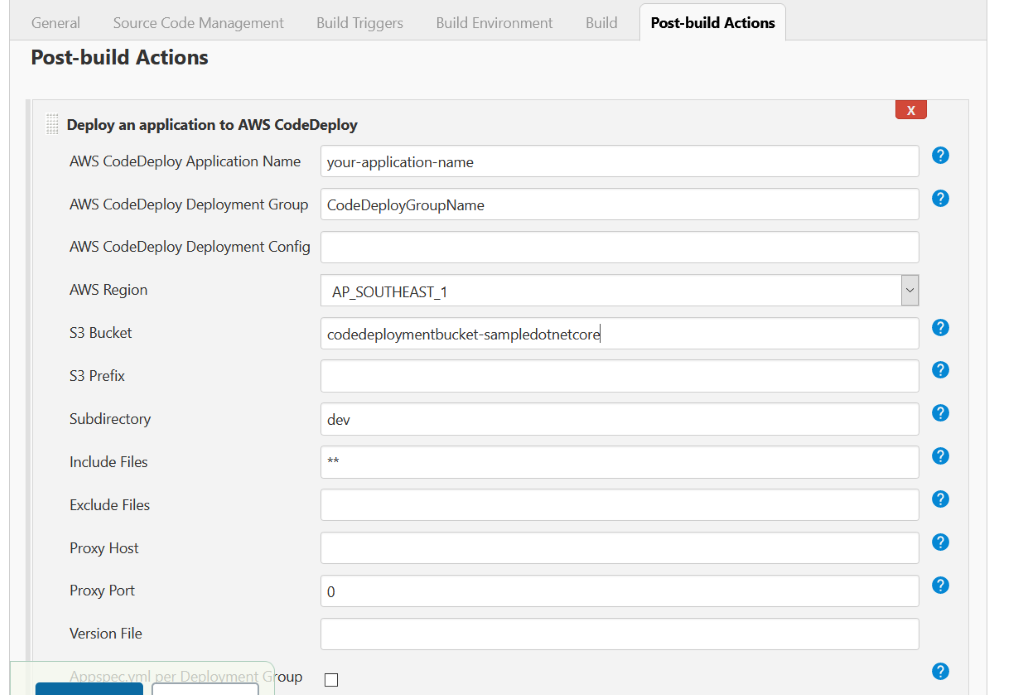



Once you have decided to develop a technical team or add more team members to your existing team using the skilled people from Mitrais, you will need to select the right candidate proposed to you by the Mitrais Account Manager.
There are many different styles and approaches to interviewing and selecting technical candidates. Everyone will have their own preferences on how best to conduct the selection. Therefore, I will not be suggesting which approach is best, but instead trying to shed some light on this process based on my experience.
Interview questions and testing for selecting technical candidates usually falls into a couple of categories.
1. Deriving questions based on the candidate’s CV
This approach is one of the most common ones. The interview can be structured by going through the candidate’s CV and asking them to explain in more detail each experience that interests the interviewer. Using this approach, dive deep into the candidate’s their experience and skill set. This can be combined with other types of interview question.
Another popular questioning technique is to ask specific questions related to their experience, what the candidates did when certain obstacles occurred, and what they would do differently now to see if they have learned from their mistakes or experience.
By asking and going through the candidate’s experience based on their CV, the interviewer can get a fairly complete picture of the depth and coverage of the candidate’s experience and skill set. This approach also allows you to assess the candidate’s communication skills.
2. Common interview questions (often asked by the HR staff)
There is a check-list of common questions usually asked by an interviewer from a HR background. They include:
- Tell me about yourself
- What do you know about this company?
- What are your strengths?
- What’s the most enjoyable part about your job and why?
- How do you handle criticism/pressure?
- What do you like the least about your current job?
- Why did you choose this career path?
If an interviewer with an HR background is not on your interviewing team, you should try to ensure that these types of open questions are included at some point.
These open questions allow you to get into more detail to assess what the candidate has done or would have done in certain situations. An experienced interviewer is able to gain more insight about the candidate using this interview technique.
3. Test the brightest minds using generic puzzle questions.
Some interviewers love this type of question to see if how a candidate will react. By including puzzle or problem-solving questions, you can see how a candidate approach different challenges from a simple question (such as why the manholes are round) to more complex questions.
The candidate might try to prepare themselves by reading the typical puzzle questions used in interviews by searching in the internet. So generic questions don’t guarantee that those with the best scores are the brightest – perhaps they are just the most prepared candidates.
4. Assess the candidate by performing a sample real-world task
When selecting a technical candidate, there is no better way to assess their capability than asking them to perform some real sample technical task and assess their performance based on their performance.
For programmers, asking them to solve real code challenges requires them to use real coding skills and show their algorithmic, programming and problem-solving skills.
For testers, asking them to design test cases for a certain type of simple application serves a similar purpose.
The drawback of this technique is that it can make the interview process time-consuming. There are some tools (such as HackerRank) that can help in testing a technical candidate using this approach.
5. Assess the candidate by asking questions based on industry processes and best-practice.
Some questions might include:
- Do you do any unit testing? If so, please explain when and how you perform unit tests.
- Do you perform code reviews? How are they performed?
- Have you prepared test cases? Who reviewed them? How were the tests executed? How were the test results reported?
- Have you ever tried to refactor your code to be more efficient? If so, please explain your experience in doing so.
This interview technique can be quite effective to be able to assess the coverage of the candidates experience and skills in regard to the engineering best practices in short period of time. However, we still need to be careful. A candidate may claim that they always perform unit testing, but that doesn’t necessarily mean that he/she is expert at designing and performing unit tests.
6. Assess the candidate by assessing on their knowledge of the fundamentals of their disciplines.
- For a Java programmer, perhaps ask the difference between double equals (“==”) and the “equals()” method in Java. We could also ask about the differences between the Java SDK and Java Runtime Environment (JRE) , or the new features of different JDK versions (e.g. Java 8 or Java 11).
- For a .NET programmer, we might ask the candidate to describe the architecture of the .NET Framework, and to name the common .NET Assembly.
- For testers, we could ask them to discuss the strengths and weaknesses of domain testing.
This interview style is quite effective and easy to use in assessing the candidate’s technical knowledge, but if the candidate uses different terminology for the same items that we refer to in our technical question, we may need to elaborate more to the candidate on what we mean by our question.
7. Elimination based on role constraint.
We can quickly assess the candidate suitability for the role by directly asking or interviewing the candidate based on constraint for the current role opening. For example, if the candidate must have at least 5 years of experience as a front-end programmer, anyone with less experience than that can be quickly removed from the list.
Another good practice is to have different people in different roles that the candidate may work with interview the candidates (in different interview sessions). This often gives you a more complete picture of the candidate, and can be a good approach since different people naturally see and focus on different aspects when interviewing. It could be a more time-consuming process, though, and may not be necessary if the assignment is a short term assignment.
What are your favourite interview questions? I usually try to combine as many of these types of question as time allows. But often time is not at our side when we are on time constraint. By knowing the characteristics of each technique, hopefully we can make the right decision to choose and combine the right ones in selecting the right technical candidate from Mitrais.